異次元(?)の少子化対策、検討中です①
予測たけし、動きます、、。
異次元の少子化対策とは、、!!

岸田総理が年頭の記者会見で「異次元の少子化対策」を掲げている。
その具体的な内容であるが、どうやら以下のようなものらしい、、。
①児童手当など経済支援の強化
②学童保育等の保育サービスの強化
③働き方改革の推進と育児休業制度などの充実
確かに上記のパッケージは、少子化要因としてこれまで議論されてきた課題の解決に向けた一歩となるだろう。だが、、、だとしたら異次元ってなんなんだ、、
つまるところ異次元とは、ゴリゴリにお金をブチ込みます、、ってことなんでしょうか、、。

すみませんが、、これでは異次元と称すに値しないでしょうッッ!!
予測たけしなりの異次元(?)の少子化対策、、提案させて頂きます。
異次元(?)の少子化対策
今回は予測たけしの特技である数値解析により、、
「モテる人も、モテない人も、チー牛も、バキ童も、等しく幸せになれる”マッチングアプリ戦略”」を考えます!!

モデル構想図は以下の通りです。
①マッチングアプリの構造を模したモデルを作成
②なにかしらの実測データをもとにモデルをフィッティング
③再現されたモデルに対して、
各個人のモテ度を最大化するための行動をまとめた
「最適戦略シナリオファイル」をGA(遺伝的アルゴリズム)で作成
④最適化された戦略シナリオファイルは、
マッチングアプリ攻略の書といえる。
これを解読することで、”万人のための少子化対策”を提案する。

、、、、、、。
まずは、数値解析モデルの構造と、フィッティングについて説明します。
マッチングアプリを模した数値解析モデルの提案
(少し細かい内容になるので、面倒な人は次の記事をご覧ください。)
数値解析モデルは、データのフィッティング及び最適戦略シナリオファイルを検討するために、大量の計算が必要になる。
よって計算速度が求められるため、Fortranで作成することとした。
計算内容は以下の通りである。
<マッチングアプリモデル>
0:男女の初期パラメータ(魅力度、投票数など)を設定
1:マッチングアプリに新たな参加者を入れる
2:いいね数がなくなった参加者or長期間存在した参加者を
アプリから削除する
3:男性側:いいね投票プロセス
(いいね投票プロセス)
a:1ステップあたりの投票数(male_poll)分だけいいねを送る
この際送付する”いいね”は、魅力度(自己認識)に応じて
確率的に分配
b:いいねを送られた側(女性)は魅力度(自己認識)を
female_polledに応じて上昇
いいねの受諾/棄却は、
いいねの送付先(男性)の魅力度(本来)と
送られた側(女性)の魅力度(自己認識)に応じて、
確率的に算出される
c:いいねが受諾された場合は
送付側(男性)の魅力度(自己認識)をmale_acceptだけ上昇
いいねが棄却された場合は
送付側(男性)の魅力度(自己認識)を
male_deniedだけ低下させる。
d:いいね送付側(男性)と送られた側(女性)の
マッチング数を更新
4:女性側:いいね投票プロセス(男性の逆)
→1〜4を適当にループさせ、
適当なタイミングで男女のいいね分布を確認
もう少し、詳述します、、。
0:男女の初期パラメータ(魅力度、投票数など)を設定
今回のモデルのいわゆる”パラメータ”は以下のような感じです。
オレンジのところは最適化計算で実際に合わせるものです。
その他、ここには示していない変数もありますが、
だいたいこんな感じです。

1:マッチングアプリに新たな参加者を入れる
1ステップの計算を実施する際に、設定した変数(base_add_OO)に応じて
参加者を増加させます。
base_addの大小によって、マッチングアプリにおける参加者の
循環が早い/遅いかを考慮することができる。
2:参加者の削除
いいね数がなくなった参加者は、行動することができないので
マッチングアプリを諦める状況が考えられる。
また、いいね数があったとしてもあまりに長期間存在する
アカウントは無いのではないか、と想定される。
これらの状況を踏まえ、初期いいね数(OO_poll)を消費しつくした
または生存している計算ステップ数がfatal_stepに達した場合に
消滅することとした。
3-4:いいね投票アルゴリズム
このステップでは”いいね”を配る状況を再現します。重要なパラメータとして、魅力度(自己認識)があります。
”実際の魅力度”は客観的に評価されるが難しいので、自分がモテている/モテていないに応じて魅力度(自己認識)を確かめていく、、という状況を想定しています。
つまり、、
●実際の魅力度 →→ 客観的(異性の)評価
●自己認識の魅力度 →→ 自分の中だけの評価
となります。
仮に実際の魅力度が低い状況であっても、
”自分はこのレベルよりは上だなぁ、、”とか考えると
マッチングが成立しないことになります。
魅力度は
・魅力度(自己認識)と同じぐらいの魅力度(実際)の人に
いいねを投票する
・自分以上の魅力度/自分ぐらいの魅力度の人の
いいねは受け入れる。
というように使われます。
これを再現するために、魅力度(自己認識)に対する確率分布を
以下の式でモデル化します。
Cは魅力度Charm(自己認識)です。
nは男性/女性それぞれのパラメータです。
これを図化すると以下のようになります。
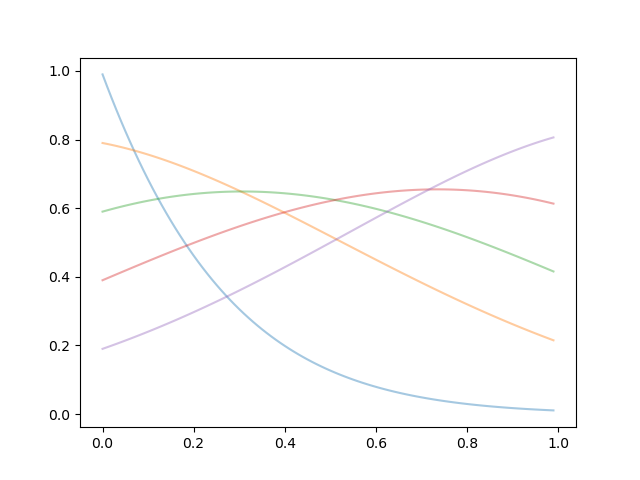
上記のような確率分布が作成されました。
この分布は、魅力度(自己認識)を中心とした
いいね投票/いいねの受け入れ、に対する確率になります。
nを大きくすると、魅力に対する差別感が強めになります。
プログラム中では、常に横軸の位置=魅力度(自己認識)を
更新していきます。
なお魅力度は、0〜nの間に必ず存在する必要があります。
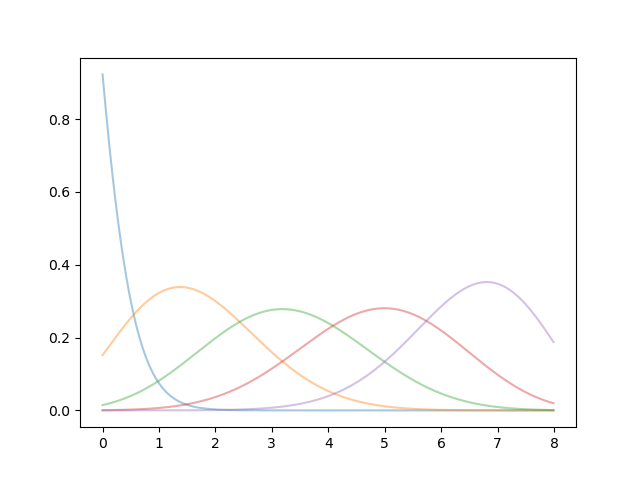
ここでは、以下の式(ロジスティクス関数的なもの)
に応じて魅力度(自己認識)を
更新することとしました。
これを図化すると以下のようになります。

縦軸=nに対応、横軸は0〜1で操作、
パラメータa,Kに応じて関数の形状が変わります
書くのが面倒になってきたのでハショりますが、、
結果的に、以下のようなモデルになってます。

実測値を再現させる
上記までで作成した数値解析モデルに対して、
実測値を再現するようにパラメータを設定していく。
パラメータの設定であるが、やはりGA(遺伝的アルゴリズム)を
用いることとした。
遺伝的アルゴリズム自体はそれほど、計算時間がかからないため
pythonのDEAPフレームワークを適応することとした。

DEAP documentation — DEAP 1.3.3 documentation
また、肝心な実測値であるが、
適当にネットで拾った以下の調査結果を用いることとした。
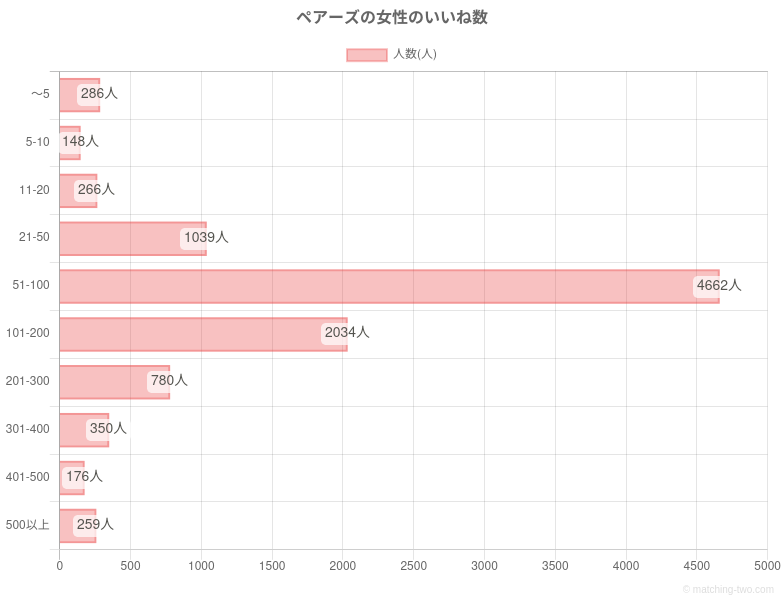
では、アルゴリズムによる最適化に任せてみましょう、、。
結果は次の記事で、、、!!